Back in April 2017, Google announced that it will be shipping Headless Chrome in Chrome 59. Since the respective flags are already available on Chrome Canary, the Duo Labs team thought it would be fun to test things out and also provide a brief introduction to driving Chrome using Selenium and Python.

Browser Automation
Before we dive into any code, let’s talk about what a headless browser is and why it’s useful. In short, headless browsers are web browsers without a graphical user interface (GUI) and are usually controlled programmatically or via a command-line interface.
One of the many use cases for headless browsers is automating usability testing or testing browser interactions. If you’re trying to check how a page may render in a different browser or confirm that page elements are present after a user initiates a certain workflow, using a headless browser can provide a lot of assistance. In addition to this, traditional web-oriented tasks like web scraping can be difficult to do if the content is rendered dynamically (say, via Javascript). Using a headless browser allows easy access to this content because the content is rendered exactly as it would be in a full browser.
Headless Chrome and Python
The Dark Ages
Prior to the release of Headless Chrome, any time that you did any automated driving of Chrome that potentially involved several windows or tabs, you had to worry about the CPU and/or memory usage. Both are associated with having to display the browser with the rendered graphics from the URL that was requested.
When using a headless browser, we don’t have to worry about that. As a result, we can expect lower memory overhead and faster execution for the scripts that we write.
Going Headless
Setup
Before we get started, we need to install Chrome Canary and download the latest ChromeDriver (currently 5.29).
Next, let’s make a folder that will contain all of our files:
$ mkdir going_headless
Now we can move the ChromeDriver into the directory that we just made:
$ mv Downloads/chromedriver going_headless/
Since we are using Selenium with Python, it’s a good idea to make a Python virtual environment. I use virtualenv, so if you use another virtual environment manager, the commands may be different.
$ cd going_headless && virtualenv -p python3 env
$ source env/bin/activate
The next thing we need to do is install Selenium. If you’re not familiar with Selenium, it’s a suite of tools that allows developers to programmatically drive web browsers. It has language bindings for Java, C#, Ruby, Javascript (Node), and Python. To install the Selenium package for Python, we can run the following:
$ pip install seleniumExample
Now that we’ve gotten all of that out of the way, let’s get to the fun part. Our goal is to write a script that searches for my name “Olabode” on duo.com, and checks that a recent article I wrote about Android security is listed in the results. If you’ve followed the instructions above, you can use the headless version of Chrome Canary with Selenium like so:
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'`
driver = webdriver.Chrome(executable_path=os.path.abspath(“chromedriver"), chrome_options=chrome_options)
driver.get("http://www.duo.com")`
magnifying_glass = driver.find_element_by_id("js-open-icon")
if magnifying_glass.is_displayed():
magnifying_glass.click()
else:
menu_button = driver.find_element_by_css_selector(".menu-trigger.local")
menu_button.click()`
search_field = driver.find_element_by_id("site-search")
search_field.clear()
search_field.send_keys("Olabode")
search_field.send_keys(Keys.RETURN)
assert "Looking Back at Android Security in 2016" in driver.page_source driver.close()`
Example Explained
Let’s break down what’s going on in the script. We start by importing the requisite modules.
The Keys provides keys in the keyboard like RETURN, F1, ALT, etc.import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
Next, we create a ChromeOptions object which will allow us to set the location of the Chrome binary that we would like to use and also pass the headless argument. If you leave out the headless argument, you will see the browser window pop up and search for my name.
In addition, if you don’t set the binary location to the location of Chrome Canary on your system, the current version of Google Chrome that is installed will be used. I wrote this tutorial on a Mac, but you can find the location of the file on other platforms here. You just need to substitute Chrome for Chrome Canary in the respective file paths.
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
driver = webdriver.Chrome(executable_path=os.path.abspath(“chromedriver"), chrome_options=chrome_options)
The driver.get function will be used navigate to the specified URL.
driver.get("https://www.duo.com")
The duo.com website is responsive, so we have to handle different conditions. As a result, we check to see if the expected search button is displayed. If it isn’t, we click the menu button to enter our search term.
magnifying_glass = driver.find_element_by_id("js-open-icon")
if magnifying_glass.is_displayed():
magnifying_glass.click()
else:
menu_button = driver.find_element_by_css_selector(".menu-trigger.local")
menu_button.click()
Now we clear the search field, search for my name, and send the RETURN key to the drive.
search_field = driver.find_element_by_id("site-search")
search_field.clear()
search_field.send_keys("Olabode")
search_field.send_keys(Keys.RETURN)
We check to make sure that the blog post title from one of my most recent posts is in the page’s source.
assert "Looking Back at Android Security in 2016" in driver.page_source
And finally, we close the browser.
driver.close().Benchmarks
Head to Headless
So, it’s cool that we can now control Chrome using Selenium and Python without having to see a browser window, but we are more interested in the performance benefits we talked about earlier. Using the same script above, we profiled the time it took to complete the tasks, peak memory usage, and CPU percentage. We polled CPU and memory usage with psutil and measured the time for task completion using timeit.
| Headless (60.0.3102.0) | Headed (60.0.3102.0) | |
|---|---|---|
| Median Time | 5.29 seconds | 5.51 seconds |
| Median Memory Use | 25.3 MiB | 25.47 MiB |
| Average CPU Percentage | 1.92% | 2.02% |
For our small script, there were very small differences in the amount of time taken to complete the task (4.3%), memory usage (.5%), and CPU percentage (5.2%). While the gains in our example were very minimal, these gains would prove to be beneficial in a test suite with dozens of tests.
Manual vs. Adhoc
In the script above, we start the ChromeDriver server process when we create the WebDriver object and it is terminated when we call quit(). For a one-off script, that isn’t a problem, but this can waste a nontrivial amount of time for a large test suite that creates a ChromeDriver instance for each test. Luckily, we can manually start and stop the server ourselves, and it only requires a few changes to the script above.
Example Snippet
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
service = webdriver.chrome.service.Service(os.path.abspath(“chromedriver"))
service.start()
chrome_options = Options()
chrome_options.add_argument("--headless")
# path to the binary of Chrome Canary that we installed earlier
chrome_options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
driver = webdriver.Remote(service.service_url, desired_capabilities=chrome_options.to_capabilities())
Snippet Explained
While there are only three lines of code that have changed, let’s talk about what’s going on in them. In order to manually control the ChromeDriver server, we have to use the ChromeDriverService. We do so by creating a service object with a path to the ChromeDriver and then we can start the service.
service = webdriver.chrome.service.Service(os.path.abspath(“chromedriver"))
service.start()
The final thing we have to do is create a WebDriver that can connect to a remote server. In order to use Chrome Canary and the headless portion, we have to pass the the dictionary of all the options since the remote WebDriver object doesn’t accept an Option object.
driver = webdriver.Remote(service.service_url, desired_capabilities=chrome_options.to_capabilities())
The Payoff
By adding the manual starting of the service, we saw the expected speed increases. The median time for the headless and headed browser to complete the tasks in the script decreased by 11% (4.72 seconds) and respectively 4% (5.29 seconds).
| Headed Browser | Headless Browser | |
|---|---|---|
| Median Time(% decrease) | 4% | 11% |
| Median Time (Seconds) | 5.29 seconds | 4.72 seconds |
DOCKER AMAZON INSTANCE
Part 1 — Use Selenium Webdriver and Chrome inside AWS Lambda
What is AWS Lambda?
Amazon explains, AWS Lambda (λ) as a ‘serverless’ compute service, meaning the developers, don’t have to worry about which AWS resources to launch, or how will they manage them, they just put the code on lambda and it runs, it’s that simple! It helps you to focus on core-competency i.e. App Building or the code.
Where will I use AWS Lambda?
AWS Lambda executes your backend code, by automatically managing the AWS resources. When we say ‘manage’, it includes launching or terminating instances, health checkups, auto scaling, updating or patching new updates etc.
You can use it with multiple services
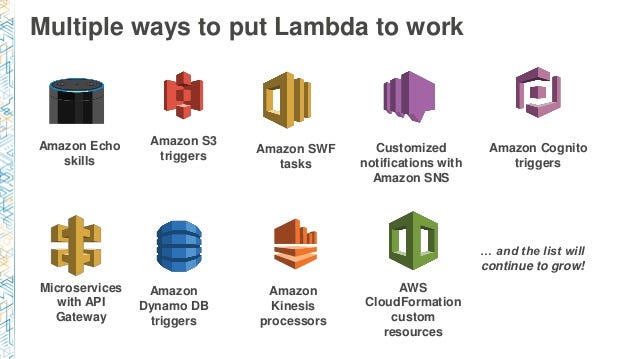
And also you can use it with Chatbot
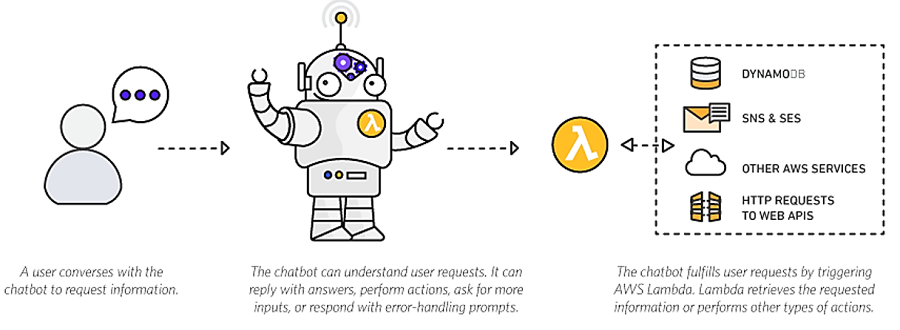
So, how does it work?
The code that you want Lambda to run is known as a Lambda function. Now, as we know a function runs only when it is called, right? Here, Event Source is the entity which triggers a Lambda Function, and then the task is executed.
Pricing in AWS Lambda
Like most of the AWS services, AWS Lambda is also a pay per use service, meaning you only pay what you use, therefore you are charged on the following parameters
- The number of requests that you make to your lambda function
- The duration for which your code executes.
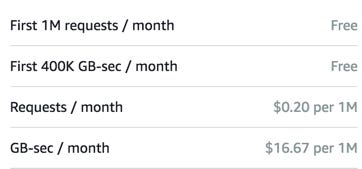
* Source: AWS official website
How to use Selenium Webdriver and Chrome inside AWS Lambda?
Note:
- We will use Chromium version 62 in headless mode
- You need to have AWS Account , if you don’t have one you can your own account from this link
1- Login to AWS Management Console and Select AWS Lambda from Compute Services
2- Click on Create new a function
3- Select option Create from scratch (default select)
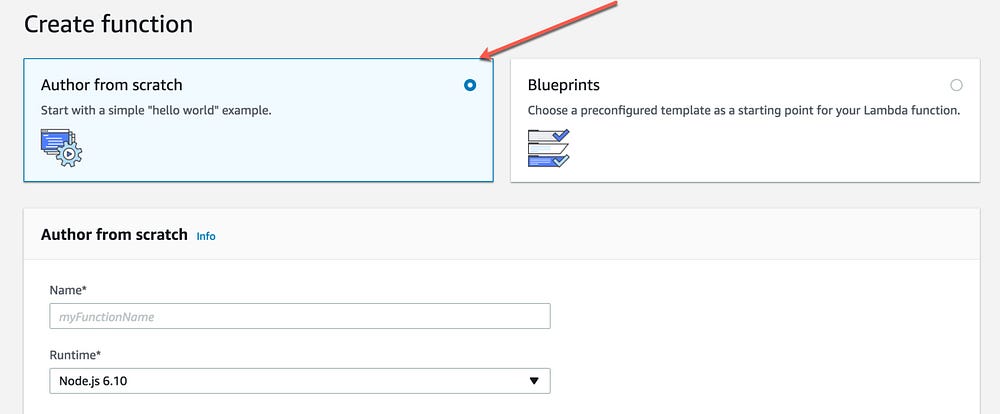
4- Add the function name and create new role and click on Create Button
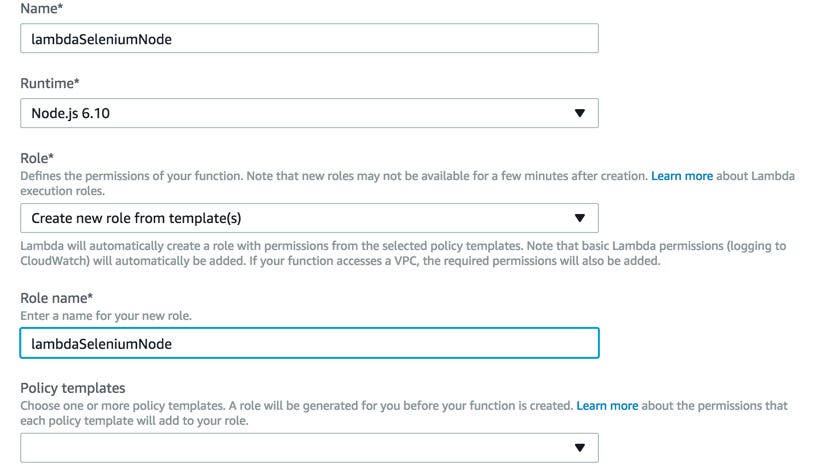
5- Congratulation you create your first Lambda function
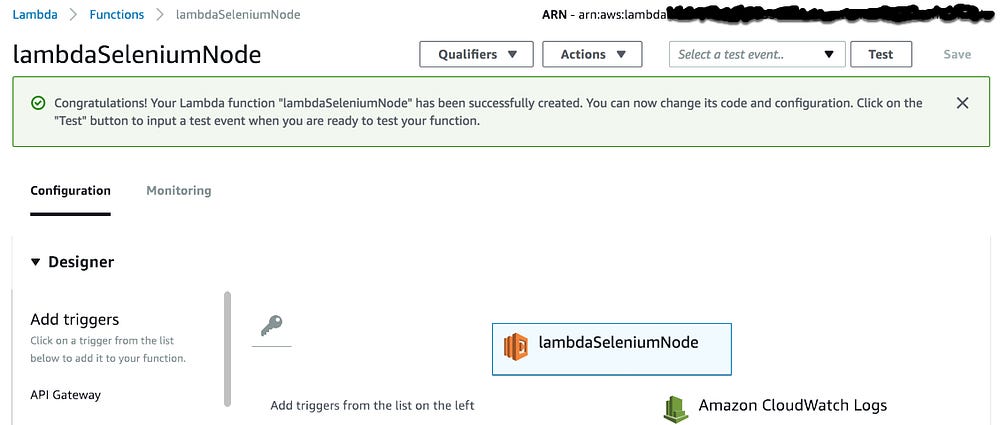
6- Select that you will upload the code from .zip folder
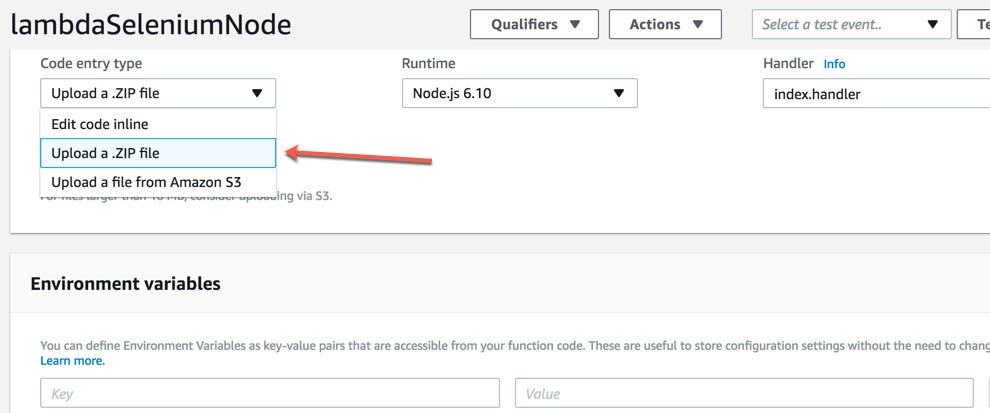
7- upload the file that you downloaded from this link

The code contains a node.js code that running selenium script using chrome in headless mode and get the page title from the url
'use strict';
exports.handler = (event, context, callback) => {
var webdriver = require('selenium-webdriver');
var chrome = require('selenium-webdriver/chrome');
var builder = new webdriver.Builder().forBrowser('chrome');
var chromeOptions = new chrome.Options();
const defaultChromeFlags = [
'--headless',
'--disable-gpu',
'--window-size=1280x1696', // Letter size'--no-sandbox',
'--user-data-dir=/tmp/user-data',
'--hide-scrollbars',
'--enable-logging',
'--log-level=0',
'--v=99',
'--single-process',
'--data-path=/tmp/data-path',
'--ignore-certificate-errors',
'--homedir=/tmp',
'--disk-cache-dir=/tmp/cache-dir'
];
chromeOptions.setChromeBinaryPath("/var/task/lib/chrome");
chromeOptions.addArguments(defaultChromeFlags);
builder.setChromeOptions(chromeOptions);
var driver = builder.build();
driver.get(event.url);
driver.getTitle().then(function(title) {
console.log("Page title for " + event.url + " is " + title)
callback(null, 'Page title for ' + event.url + ' is ' + title);
});
driver.quit(); };
8- In Basic setting section you need to increase the memory to the max value and also increase the timeout to be 5 min.
Then on Save button to upload your code and apply the changes
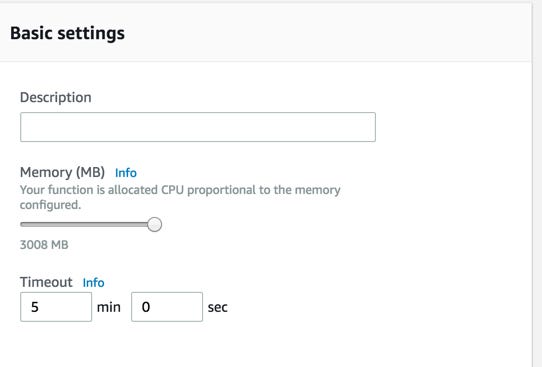
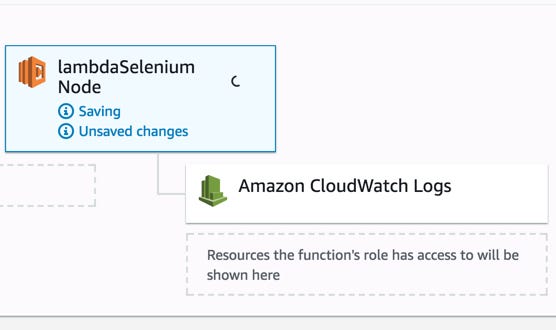
9- Wait the saving until the success status displayed
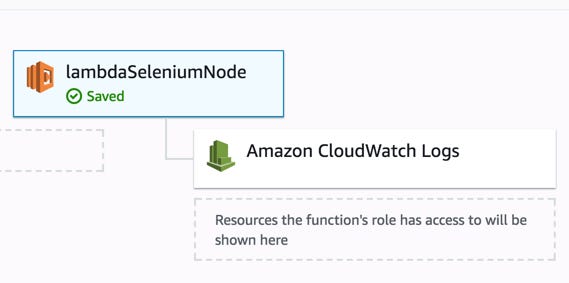
10 — Now we will add a Test event using a JSON file and add the url as a test data
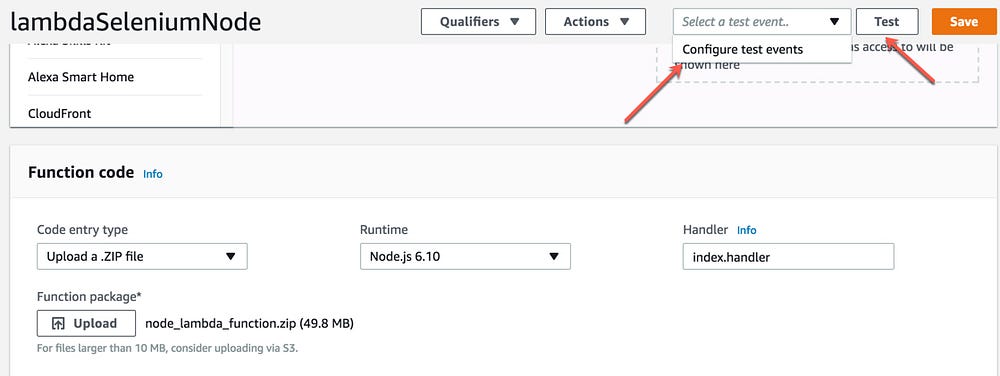
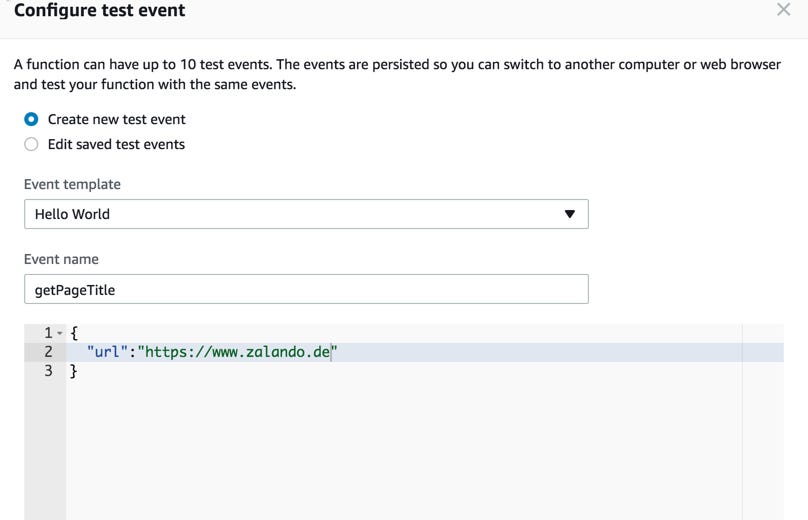
11- Save your test event and click on Test button
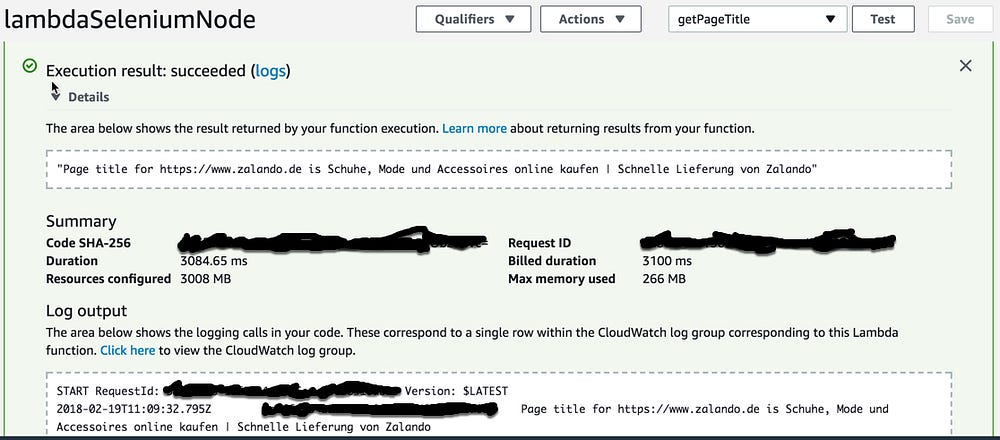
Congratulation the test passed and the result will be the page title of the url that you are using